# 工作流
用户自定义药物发现工作流是现代药物研发的重要组成部分。在这一流程中,研究人员可以根据实验目标和研究需求,灵活组合和配置多种药物设计计算模块与工具,构建一条高效、完整的药物发现流水线。
例如,用户可从早期化合物库筛选开始,将化合物库管理、分子属性预测、药效团模型匹配、虚拟筛选等步骤串联起来,每一步可能涉及不同的专业工具,如:
化合物库筛选阶段 使用化合物数据库管理系统进行初步过滤,筛选出符合条件的候选化合物。
分子属性预测阶段 使用QSAR模型或计算化学方法预测化合物的ADME/T性质(吸收、分布、代谢、排泄/毒性),为后续的药物开发提供参考。
药效团模型匹配和虚拟筛选阶段 使用分子对接软件预测化合物与靶标蛋白的结合模式及亲和力,筛选出可能具备药效的分子。
通过此自定义工作流,实验数据和结果能自动衔接,实现高效的自动化流转,减少手动操作带来的误差。此外,任务间的并行执行大幅加速整个药物发现流程。研究人员还可通过实时监控和数据分析优化工作流,提高药物研发的成功率与效率。
# 使用步骤
# 第一步:输入蛋白质
上传目标蛋白的结构文件或输入蛋白质ID,为后续分子对接和亲和力预测提供靶标信息。系统支持上传.pdb格式的蛋白质文件,或通过蛋白质ID获取结构数据。

- 上传文件:支持
.pdb格式的三维结构文件,确保上传的文件完整并符合标准格式。 - 输入蛋白质ID:若已知靶标的PDB ID,可直接输入ID,系统将自动拉取并加载相应的蛋白质数据。
# 第二步:输入小分子
上传包含小分子结构信息的文件或直接输入数据。小分子信息是用于虚拟筛选的基础,系统支持以下几种输入方式:
输入小分子SMILES数据 手动输入小分子的SMILES格式字符串,系统会根据此分子描述生成小分子的化学信息。
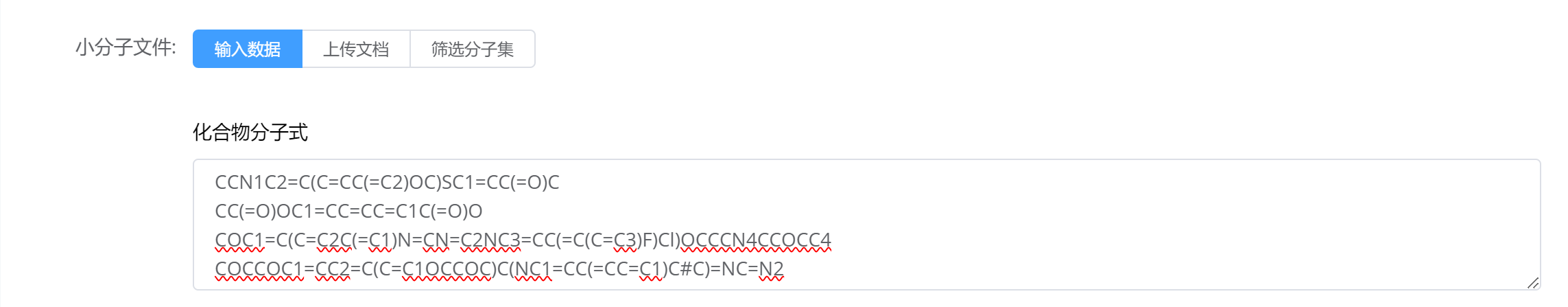
上传小分子SMILES文件 若有大量小分子候选物,可上传包含多条SMILES字符串的
.csv文件,文件每一行包含一个小分子。确保文件格式正确,以便系统顺利读取。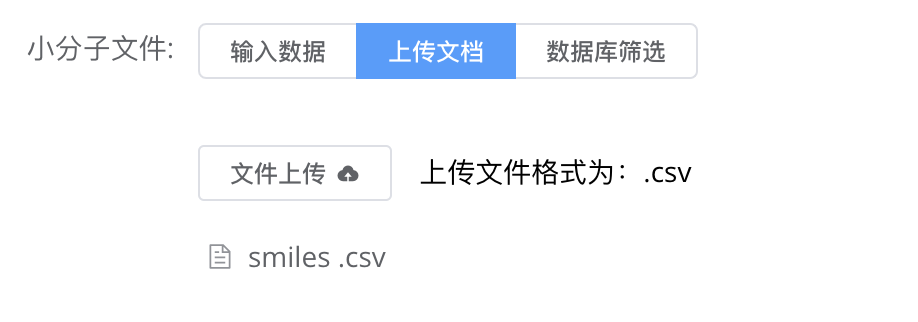
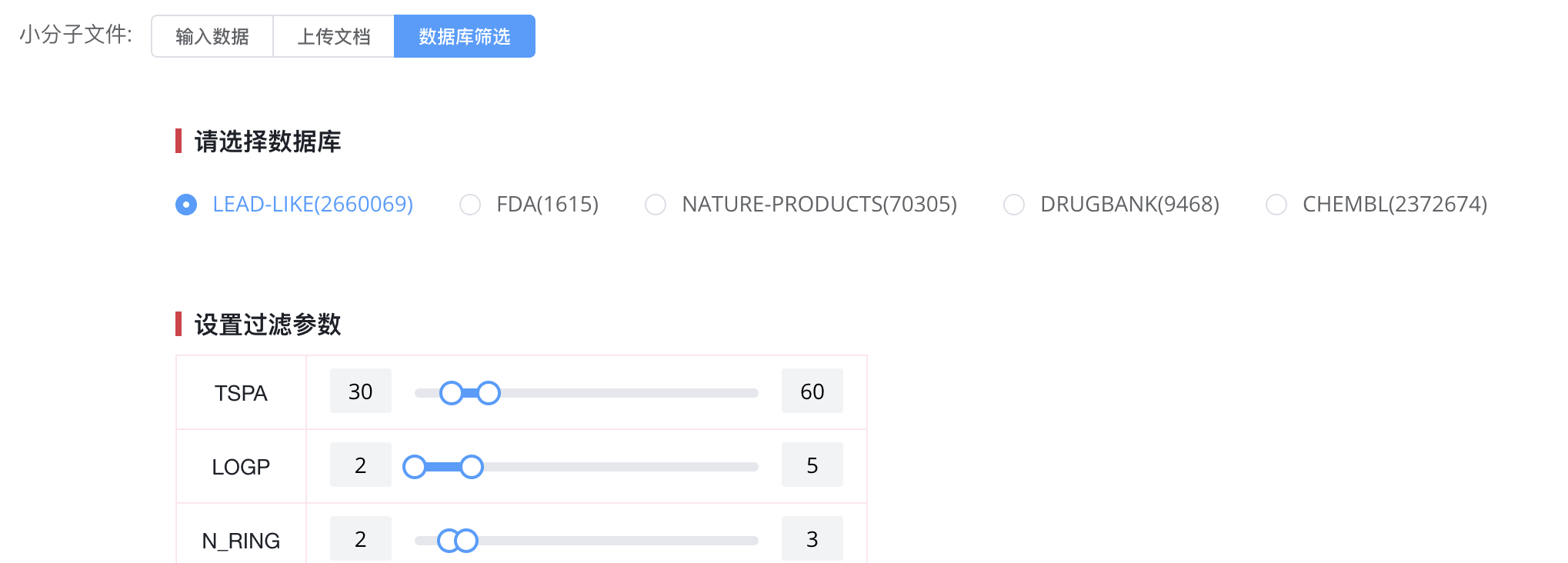
筛选分子集 在已有分子库中选择一部分小分子作为候选集合,适用于从大型分子库中筛选特定分子用于实验。系统提供筛选选项,可按分子质量、极性等标准筛选。
# 第三步:添加工作流模块
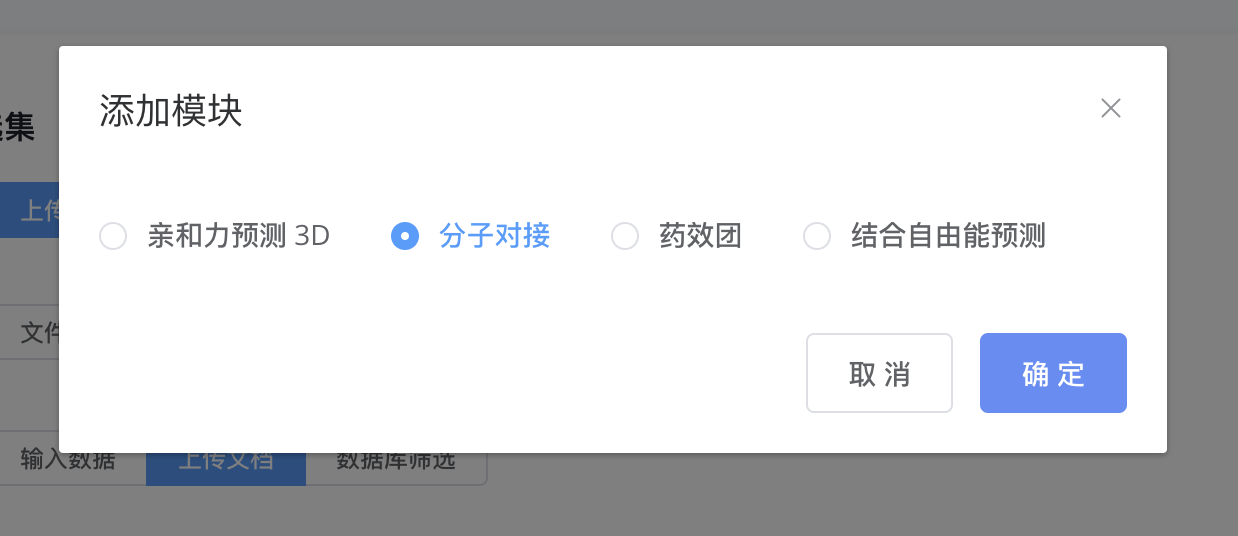
根据研究需求,用户可以灵活添加不同的分析模块,构建自定义工作流。因为输入数据已经给定,在添加模块中用户只需要给定模块参数即可。以下模块为常见选择:
添加分子对接模块 用于预测小分子与蛋白质靶标的空间对接方式。分子对接模块提供对分子结合位点和对接构象的评估,帮助识别有较强亲和力的结合方式。
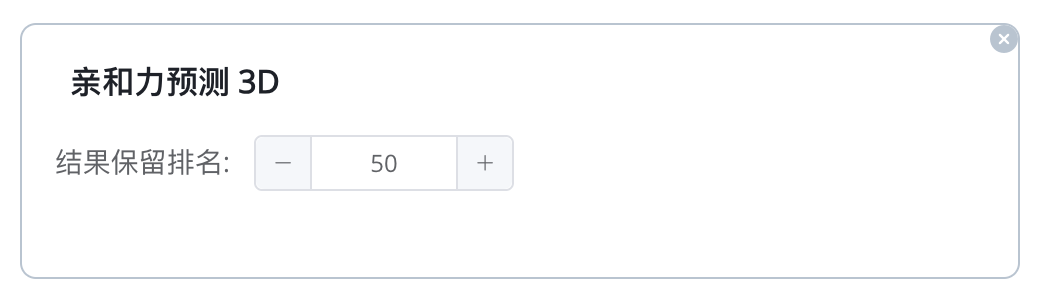
添加亲和力预测(3D)模块 基于蛋白质和小分子的三维结构进行结合亲和力打分,帮助评估分子间相互作用的强度。此模块特别适合于筛选出高结合能力的候选药物。
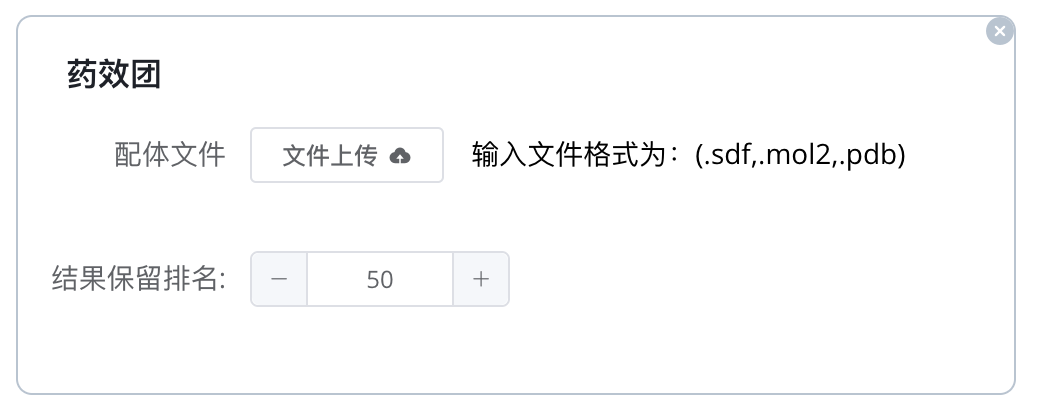
添加药效团模块 通过药效团模型匹配,筛选符合特定药效团特征的小分子,有助于识别在结构上具有药效潜力的化合物。
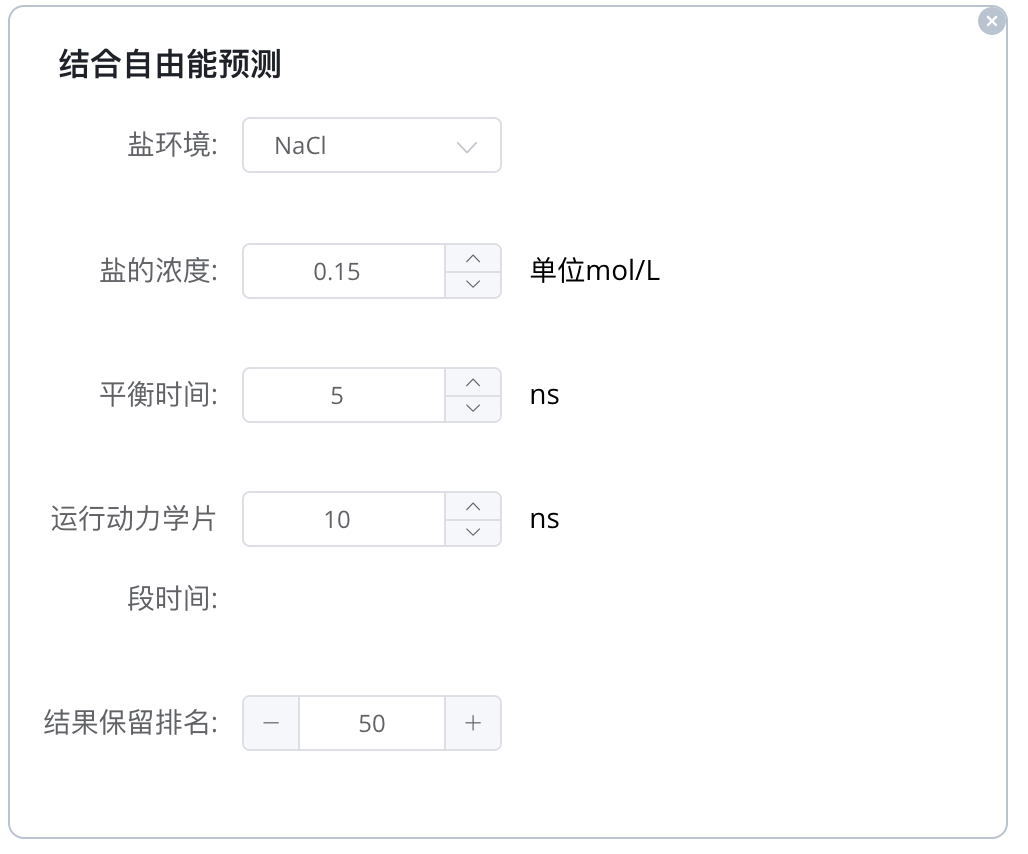
添加结合自由能模块 预测小分子和蛋白质在结合时的自由能变化,以判断分子在生物环境中稳定结合的可能性。结合自由能是预测药物有效性的重要参考值。
# 第四步:提交执行
完成所有设置后,点击“提交执行”按钮,系统将按照工作流顺序自动进行计算和分析。每个模块生成的结果文件会自动保存,并支持导出至本地或存入实验数据库(未来支持)中。